学习如何设置robots.txt和meta robots标签对于SEO的成功至关重要。 本文将帮助大家全面了解关于Meta Robots Tag和Robots.txt的所有内容,让大家在设置Meta Robots Tag和Robots.txt的时候少走弯路。
Meta Robots标签 vs. Robots.txt
在深入了解Meta Robots标签和Robots.txt文件的基础知识之前,最重要的是要知道,在SEO中没有哪一方比另一方更好。
Robots.txt文件可以指导搜索引擎爬虫了解整个网站,而Meta robots标签是针对某个特定页面的。
我个人比较喜欢在一些情况下用Meta Robots标签,而其他SEO专家可能只是用简单的robots.txt文件。使用什么样的方式都没错,这是根据你的经验的个人偏好。
什么是Robots.txt?
Robots.txt文件会告诉爬虫什么内容可以抓取,什么内容不可以抓取。它是机器人排除协议(REP)的一部分。
Googlebot就是一个典型的爬虫。Google部署了Googlebot来抓取网站,并记录该网上上的信息,以了解如何在Google的搜索结果中对网站进行排名。
你通过在网址后添加/robots.txt来找到任何网站的robots.txt文件,如下所示:
www.mywebsite.com/robots.txt
Robots.txt长什么样?
以下是robots.txt文件的基本格式:
Sitemap: [站点地图的URL地址] User-agent: [爬虫身份] [指令1] [指令 2] [指令 ...] User-agent: [另一个爬虫身份] [指令1] [指令 2] [指令 ...]
如果你以前从未看过这些内容,你可能会觉得很难。但实际上,它的语法非常简单。简而言之,你可以通过在文件中指定user-agents(用户代理)和directives(指令)来为搜索引擎蜘蛛分配抓取规则。
下面是一个基本的robots.txt文件:
User-agent: * Disallow: /
User-agent后面星号 * 告诉爬虫这个robots.txt文件是针对来到网站的所有爬虫。Disallow后面的斜杠 “/” 告诉爬虫不要爬取该站点的任何页面。
下面是Moz的robots.txt文件示例:
sitemap: https://moz.com/sitemaps-1-sitemap.xml User-agent: * Allow: /researchtools/ose/$ Allow: /researchtools/ose/dotbot$ Allow: /researchtools/ose/links$ Allow: /researchtools/ose/just-discovered$ Allow: /researchtools/ose/pages$ Allow: /researchtools/ose/domains$ Allow: /researchtools/ose/anchors$ Allow: /products/ Allow: /local/ Allow: /learn/ Allow: /researchtools/ose/ Allow: /researchtools/ose/dotbot$ Disallow: /products/content/ Disallow: /local/enterprise/confirm Disallow: /researchtools/ose/ Disallow: /page-strength/* Disallow: /thumbs/* Disallow: /api/user?* Disallow: /checkout/freetrial/* Disallow: /local/search/ Disallow: /local/details/ Disallow: /messages/ Disallow: /content/audit/* Disallow: /content/search/* Disallow: /marketplace/ Disallow: /cpresources/ Disallow: /vendor/ Disallow: /community/q/questions/*/view_counts Disallow: /admin-preview/*
可以看到,他们用user-agent和指令来告诉爬虫应该去抓取哪些页面,稍后我会对此深入分析。
重要提示
大多数搜索引擎都会遵循规则,但有少部分的搜索引擎则会无视这些规则。
Google的爬虫会遵守robots.txt文件中的声明。
如何创建一个robots.txt文件?
如果你的网站还没有robots.txt文件,那么做一个也是很简单的。只需要打开一个空的.txt文件(记事本文件)然后按照要求填写指令。比如,你希望搜索引擎不要抓取你的/admin/目录,你可以像下面这样填写:
user-agent: * Disallow: /admin/
你还可以继续往里面添加指令,直到满足你的需求为止,然后将文件保存为“robots.txt”即可。
除此之外,你还可以使用robots.txt生成工具来制作,好比这个:
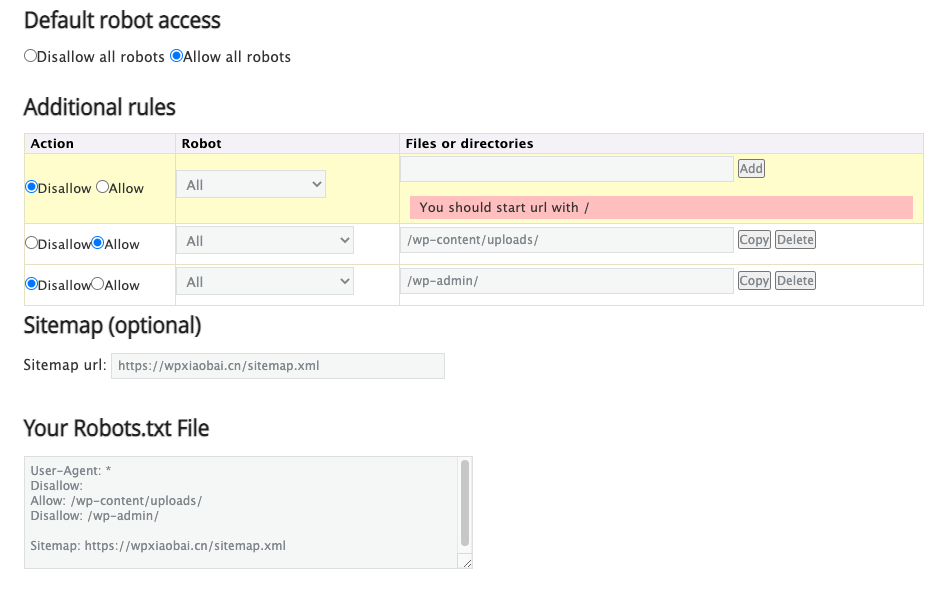
利用类似这样工具的优势就是你可以避免指令语法错误。这个非常重要,因为一个小的语法错误都会导致灾难性的后果,还是谨慎一些比较好。
劣势就是,这些工具在某些程度上无法自由的自定义。
为什么Robots.txt非常重要?
我都记不清有多少用户在网站迁移后,或者新建网站后过来问我:为什么做了几个月的优化,我的网站排名仍然没有起来?
我只能说60%的原因是因为robots.txt文件没有正确的更新。也就是说你的robots.txt文件看起来还是像下面这样:
User-agent: * Disallow: /
这样会阻止所有的爬虫去抓取你网站的内容。
Robots.txt重要的另一个原因是Google有一个叫抓取预算的东西。
Google说:
Googlebot旨在成为网络的良好公民。 抓取是其首要任务,同时要确保它不会降低普通用户访问该网站的用户的体验。 我们将此称为“抓取速度限制”,它限制了给定站点的最大抓取速度。
简而言之,这表示Googlebot可以用来抓取网站的并发数,以及两次抓取之间必须等待的时间。
所以,如果你的网站比较大,且有一些质量不高的页面,则可以通过robots.txt文件来告诉Google 去 “Disallow” 这些页面。
这样可以节省网站的抓取预算,让Google仅抓取你希望Google为你排名的高质量页面。
Google 在2019年7月宣布了一项提案,针对robots.txt文件中包含的规则提出了一个正式的互联网标准。
在过去的25年终,机器人排除协议(REP)中列出的那些规则一直都是非正式的标准。尽管REP已被大部分搜索引擎采用,但它仍不是官方的。这意味着开发者可以自由的对其进行解释说明。此外,它从未针对当今的用例进行过更新。

正如Google所说,这给网站运营带来了障碍,因为模棱两可的事实标准使正确编写规则变得困难。
为了消除这个障碍,Google已经撰写了如何在当前的网站上使用REP的草案,并且将其提交给了互联网工程任务组(IETF)进行审核。
Google解释了草案中包含的内容:
拟议的REP草案反映了20多年来被约5亿个网站依赖的robots.txt规则的经验总结,这些规则是Googlebot和其他主要爬虫程序都在使用的。 这些规则使发布者可以决定网站的哪些页面可以被爬取并向感兴趣的用户展示指定的内容。
该草案不会改变1994年制定的任何规则,只是针对现代网站进行了更新。
一些更新的规则包括:
- 任何基于URI的传输协议都可以使用robots.txt。 不再局限于HTTP。 也可以用于FTP或CoAP。
- 开发人员必须至少解析robots.txt的前500 kb。
- 新的最长缓存时间或缓存指令值(如果有的话)为24小时,这使网站所有者可以灵活随时更新自己的robots.txt。
- 当robots.txt文件由于服务器故障而无法访问时,已知的不允许抓取的页面将在相当长的一段时间内不会被抓取。
Robots.txt基础知识
如何使用Robots.txt
使用robots.txt对于SEO成功至关重要。但是,如果不了解它的工作原理,面对网站没有排名的问题会让你抓耳挠腮。
搜索引擎会根据你在robots.txt中使用的指令和表达式对你的网站进行抓取和编制索引。以下是常见的robots.txt指令:
User-agent: * —— 这是robots.txt文件的中的第一行指令,用于向爬虫说明你希望他们在你的网站上进行抓取的规则。星号则表示允许所有的爬虫。
User-agent: Googlebot ——这句话意思是你只希望Googlebot对你的网站进行抓取。
Disallow: / ——该指令告诉爬虫不要对网站进行任何页面的抓取。
Disallow: ——该指令告诉爬虫对网站所有页面进行抓取。
Disallow: /staging/ ——该指令告诉爬虫忽略你的测试站点。
Disallow: /ebooks/*.pdf —— 该指令告诉爬虫忽略所有可能导致重复内容问题的PDF格式文件
User-agent: Googlebot
Disallow: /images/ —— 这两条指令表示仅不允许Googlebot抓取网站所有的图片。
* —— 星号为可以代表任何字符的通配符
你不仅可以使用通配符(*)将指令应用于所有用户代理,同时可以在声明指令时用来匹配雷同的URL。例如,如果你想防止搜索引擎访问网站上的参数化产品类别URL,可以像这样列出它们:
User-agent: * Disallow: /products/t-shirts? Disallow: /products/hoodies? Disallow: /products/jackets? …
但是这并不简洁,你可以利用通配符,简写成下方这样:
User-agent: * Disallow: /products/*?
这个例子就是屏蔽了所有的搜索引擎爬虫抓取 /product/ 目录下,所有包含问号(?)的链接。换句话说就是屏蔽了所有带有参数的产品链接。
$ —— 用于匹配以特定字符结尾的URL
在指令最后加入”$”。比如,如果你想屏蔽所有以 .pdf结尾的链接,那么你可以这样设置 robots.txt:
User-agent: * Disallow: /*.pdf$
这个例子中,搜索引擎无法抓取任何以 .pdf 结尾的链接,意味着搜索引擎无法抓取 /file.pdf,但是搜索引擎可以抓取这个 /file.pdf?id=68937586,因为它没有以”.pdf“结尾。
给WordPress创建robots.txt文件,我一般使用Yoast插件。但是,在你开始创建你的robots.txt文件之前,首先需要记住下面的一些基本知识:
- 正确设置robots.txt的格式。 SEMrush的例子很好地说明了应如何正确设置robots.txt的格式。 你可以看到其结构遵循以下模式:User-agent→Disallow→Allow→Host→Sitemap。 这使搜索引擎爬虫能够以正确的顺序访问类别和网页。
- 确保你要“Allow”或“Disallow”的每个URL都放置咋单独的一行上面,并且不要以空格分隔。
- 使用小写字母给robots.txt命名。
- 不要使用除 * 和 $ 以外的其他特殊符号。其他符号不会被识别。
- 针对不同的子域名分别创建robots.txt。
robots.txt只在当前所属的子域名中生效。如果你需要控制不同子域名的抓取规则,那么就需要分开设置不同的robots.txt文件。
例如 “sample.com”和“blog.sample.com”是两个独立的网站,那么你就需要有两个robots.txt文件,一个放在主站的根目录中,一个放在博客站的根目录中。 - 在robots.txt中使用#来添加注释,爬虫会忽略#后面的内容。
使用注释功能,可以向开发者说明你的robots.txt指令的用途。# This is a comment User-agent: * Disallow:
- 如果某个页面在robots.txt中是Disallow的,那么链接权重不会传递。
- 不要用robots.txt来保护或组织敏感数据。
需要用Robots.txt隐藏的内容
Robots.txt文件通常用于从SERP中排除特定的目录、类别或页面。
你可以使用“Disallow”指令去排除。
以下是一些使用robots.txt文件去隐藏的常见页面:
- 具有重复内容的页面(通常是为打印适配的内容)
- 分页页面
- 动态产品和服务页面
- 账户相关的页面
- 管理员后台的页面
- 购物车
- 客服对话页面
- Thank you页面
这些对电子商务网站非常有用。

下面是一个禁止thank you页面的例子
User-agent: * Disallow: /videos/ Disallow: /thank-you/ Sitemap: https://www.leadfeeder.com/sitemap.xml
一定要记住,不是所有的爬虫都会遵循你在robots.txt中设置的规则。
一些不规矩的爬虫会完全忽略你的robots.txt文件,所以确保不要在被禁止抓取的页面上保存敏感数据。
常见的robots.txt错误
错误1:文件名包含大写字母
robots.txt是唯一可用的名字,一定要全部小写,不能是Robots.txt,也不能是ROBOTS.TXT。
涉及到SEO的,一定坚持都用小写。
错误2:没有把robots.txt放在根目录
如果你想要你的robots.txt文件被爬虫发现,一定要把它放在网站根目录。
错误示范
www.mysite.com/tshirts/robots.txt
正确示范
www.mysite.com/robots.txt
错误3:格式不正确的User-Agent
错误示范
Disallow: Googlebot
正确示范
User-agent: Googlebot Disallow: /
错误4:在一行“Disallow”指令中写了多个分类
错误示范
Disallow: /css/ /cgi-bin/ /images/
正确示范
Disallow: /css/ Disallow: /cgi-bin/ Disallow: /images/
错误5:User-Agent指令的值为空
错误示范
User-agent: Disallow:
正确示范
User-agent: * Disallow:
错误6:在Host指令中镜像网站和网址
在使用Host指令时请务必谨慎,要让搜索引擎正确理解你要表达的意思:
错误示范
User-agent: Googlebot Disallow: /cgi-bin
正确示范
User-agent: Googlebot Disallow: /cgi-bin Host: www.site.com
如果网站使用了HTTPS,则正确的应该是:
User-agent: Googlebot Disallow: /cgi-bin Host: https://www.site.com
错误7: 列出目录里所有的文件
错误示范
User-agent: * Disallow: /pajamas/flannel.html Disallow: /pajamas/corduroy.html Disallow: /pajamas/cashmere.html
正确示范
User-agent: * Disallow: /pajamas/ Disallow: /shirts/
错误8:没有Disallow指令
Disallow指令是必须有的,这样搜索引擎爬虫才能了解你的意图。
错误示范
User-agent: Googlebot Host: www.mysite.com
正确示范
User-agent: Googlebot Disallow: Host: www.mysite.com
错误9:屏蔽整个网站
错误示范
User-agent: Googlebot Disallow: /
正确示范
User-agent: Googlebot Disallow:
错误10:错误的HTTP响应头
错误示范
Content-Type: text/html
正确示范
Content-Type: text/plain
错误11:没有SItemap
一定要把你的站点地图放在robots.txt文件的底部。
错误示范
User-agent: * Disallow: /button Disallow: /add Disallow: /ajax
正确示范
User-agent: * Disallow: /search/*?* Disallow: /en/* Sitemap: https://mailchimp.com/sitemap.xml
错误12:使用noindex
Google在2019年宣布不再承认robots.txt中使用的noindex指令。所以用下面展示的正确示范的方式吧!
错误示范
User-agent: * Disallow: / Noindex: thank-you
正确示范
User-agent: * Disallow: thank-you
错误13:在robots.txt文件中Disallow了一个页面,但仍有链接指向该页面
如果你在robots.txt文件中Disallow了一个页面,但仍有内部链接指向该页面的话,Google仍会对该页面进行抓取。
你需要删除那些链接才能让爬虫完全停止抓取该页面。
如果你不确定,可以在Google Search Console覆盖率报告中查看哪些页面已被编入索引。
你应该会看到类似以下的内容,而且你还可以使用Google的robots.txt测试工具。
但是,如果你使用的是Google的移动友好的测试工具,则它不会遵循robots.txt文件中的规则。

如何检测robots.txt文件中的问题
Robots.txt很容易出现错误,因此检测是十分有必要的。
为了检测robots.txt相关问题,你可以在 Google Search Console 中查看的 “Coverage(索引覆盖率)”报告。下面就是一些常见的错误,包括它们的含义以及解决方法:
是否需要检查与某个页面相关的错误?
将指定的URL放入GSC的URL Inspection tool(网址检测)。如果被robots.txt屏蔽了,那么就会像下方这样显示:
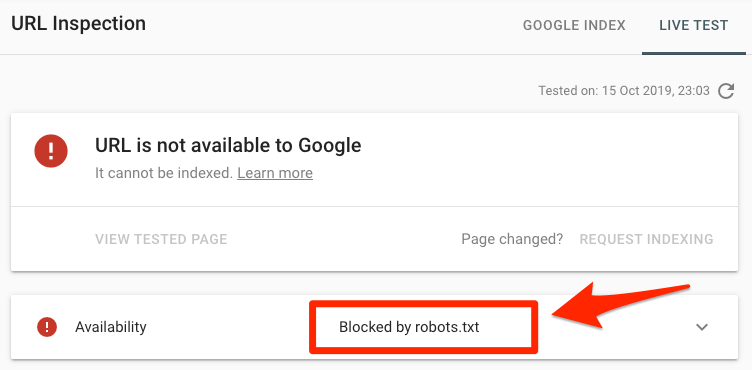
提交的URL被robots.txt屏蔽了
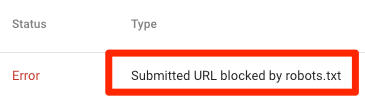
这说明在你提交的sitemap中,至少有一条URL被robots.txt屏蔽了。
如果你创建的sitemap没问题,且不包含canonicalized(规范标签)、noindexed(指定不索引)、redirected(跳转)等页面,那么你提交的所有的链接都不应该被robots.txt屏蔽。如果被屏蔽了,你需要调查受影响的页面,然后相应地调整robots.txt文件,删除阻止该页面的指令。
你可以使用谷歌的robots.txt检测工具来查看哪条指令在阻止访问。在修改的时候你需要小心,因为很容易就会影响到其它的页面以及文件。
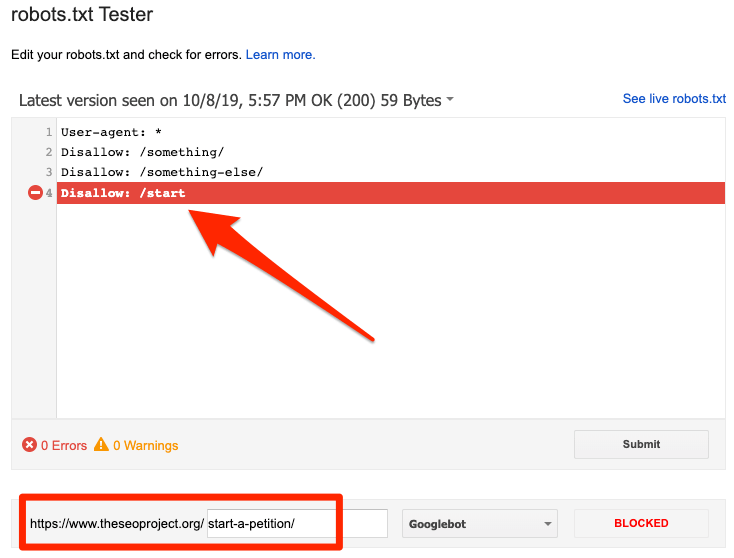
被robots.txt屏蔽了
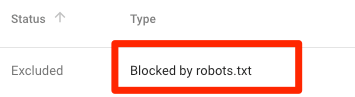
这说明,当前你有内容被robots.txt屏蔽了,但是暂时没有被Google索引。
如果这个内容很重要,并且需要被索引,删除robots.txt中的阻碍抓取的指令。(同时你得注意这个内容是否被索引标记标注为不索引状态)如果你需要屏蔽的内容也是不需要谷歌索引的话,那么你可以去掉屏蔽抓取的指令,然后使用meta robots标签、或者是x-robots HTTP头部指令进行屏蔽——这样就可以保证内容不被索引。
Tips如果想要将页面从索引中删除,必需先移除抓取阻碍。否则,谷歌无法抓取到页面的noindex(不索引)标记、或是HTTP头部指令——这样只会让搜索引擎保持原有的索引状态。
索引但是被robots.txt屏蔽
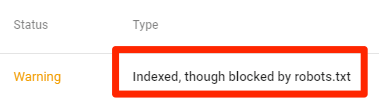
这说明虽然一部分内容被robots.txt屏蔽了,但是依然是被谷歌索引的。
同样道理,如果你希望从搜索引擎中去除该内容,robots.txt并不是最好的选择。最好使用meta robots标签、或者是x-robots HTTP请求头指令防止被索引。
如果你是不小心屏蔽了这个内容,并且希望内容被谷歌索引的话,只需要在robots.txt中移除阻碍索引的指令即可。这样可以帮助你的内容更好的展现在SERP当中。
Meta Robots标签是什么?
Meta robots标签(也称为Meta robots指令)是HTML代码,用来高速搜索引擎爬虫如何抓取和索引网站上的页面。
Meta robots标签需要添加到网页的<head>部分,例如:
<head>
...
<meta name="robots" content="noindex" />
...
</head>
Meta robots标签由两部分组成。
标签的第一部分是 name=””,这里是用来指定user-agent的,例如 name=“Googlebot”。
第二部分是 content=””,这里你可以告诉爬虫你想让他们做什么。
Meta Robots标签的类型
Meta robots标签有两种类型:
- Meta robots tag
- X-robots-tag
类型1:Meta Robots Tag
SEO营销人员通常会使用Meta Robots Tag。它可以让你告诉User-Agent,例如Googlebot,去抓取特定区域。
看下面这个例子:
<meta name ="googlebot" content ="noindex,nofollow">
这个meta robots tag告诉Google的爬虫Googlebot不要在搜索引擎中为该页面编制索引,也不要跟踪任何反向链接。
因此,该页面不会显示在SERP中。
如果你给不同的user-agent不同的指令,则需要为每个爬虫创建单独的标签。
Glenn Gabe在这篇研究报告中说明了为什么一定不要把meta robots tag放在<head>之外。
类型2:X-robots-tag
X-robots-tag可以让你做跟meta robots tag一样的事情,但是它是放在HTTP请求头中的。
从本质上讲,它比meta robots tag提供的功能更多。但是你需要去访问php, .htaccess或者服务器文件。
例如:如果想要屏蔽图像或视频,而不是整个页面,则应该使用X-robots-tag,而不是Meta Robots Tag。
Meta Robots Tag参数
在html代码中有很多种使用Meta Robots Tag指令的方法。但是,首先,你需要了解这些指令是什么以及它们的作用。
下面来详细了解一下Meta Robots Tag的指令:
- all – 对内容索引没有限制。该指令也是Meta Robots Tag的默认指令,它对搜索引擎的工作没有影响。可以用all指令作为 index, follow的快捷方式。
- index – 允许搜索引擎在他们的搜索结果中将该页面编入索引。这是默认值,你不需要在页面中添加这个指令。
- noindex – 从搜索引擎索引和搜索结果中删除页面。添加了noindex的页面可以让搜索引擎无法找到该页面或无法点击。
- follow – 允许搜索引擎跟随该页面上的内链和外部反向链接。
- nofollow – 不允许搜索引擎跟随该页面上的内链和外部反向链接,所以该页面上的链接不会传递链接权重。
- none – 与noindex和nofollow标签的功能相同。
- noarchive – 不要在SERP中显示“保存的副本”链接。
- nosnippet – 不要在SERP中显示此页面的扩展描述版本。
- notranslate – 不要在SERP中提供此页面的翻译。
- noimageindex – 不要索引此页面上的图像。
- unavailable_after: [RFC-850 date/time] – 在指定日期之后不要在SERP中显示此页面,日期格式为RFC 850标准。
- max-snippet – 为元描述中的字符数规定一个最大数字。
- max-video-preview – 规定视频预览的最大秒数。
- max-image-preview – 规定图像预览的最大尺寸。
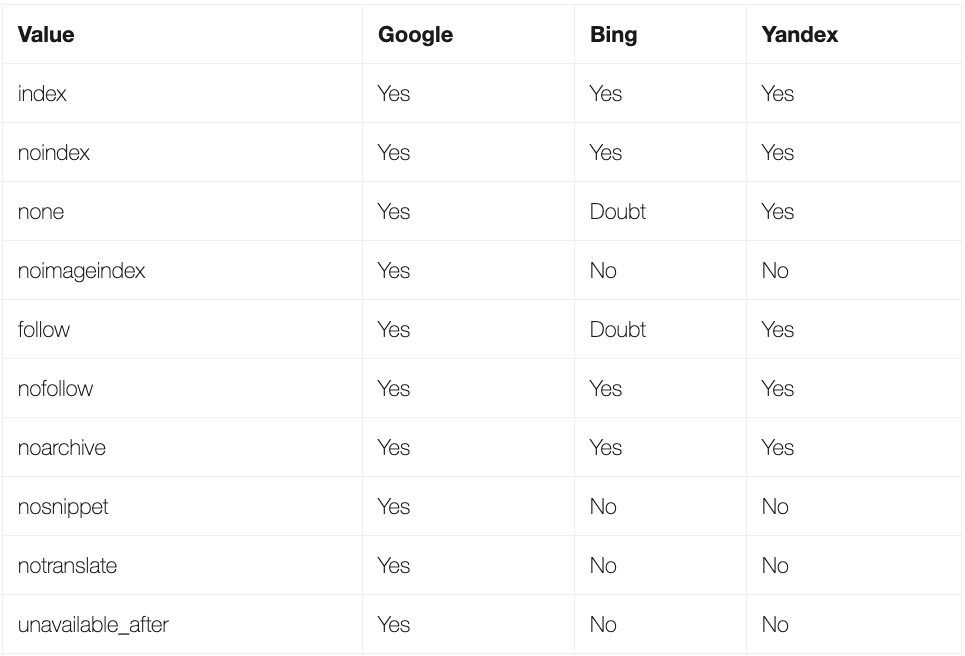
不同的搜索引擎会接受不同的meta-tag参数,详细如下:
如何使用Meta Robots Tags
如果你是基于WordPress的网站,那么有很多可选的插件可以处理Meta Robots Tag。我推荐使用Yoast,这是一个全功能WordPress的SEO插件,提供了非常丰富的SEO相关的功能。
不过,除了Yoast,还有很多其他的插件,例如Meta Tags Manager和GA Meta Tags。
使用Meta Robots Tag需要注意一下三点:
注意字母的大小写。搜索引擎可以识别大小写的属性,值和参数。 我建议你坚持使用小写字母以提高代码的可读性。 另外,如果你对外提供SEO服务,则最好养成使用小写字母的习惯。
避免使用多个<meta>标签。使用多个Meta标签会导致代码冲突。 你可以在<meta>标签中使用多个值,例如:<meta name =“ robots” content =“ noindex,nofollow”>。
不要使用有冲突的Meta标签,以避免索引错误。如果你的页面有多个<meta>标签的代码,例如<meta name =“ robots” content =“ follow”>和<meta name =“ robots” content =“ nofollow”>,那么爬虫只会考虑使用“ nofollow” 。 这是因为爬虫会首先考虑带有限制性质的值。
Robots.txt和Meta Robots标签可以协同工作
我在实际工作中遇到最大的错误之一是,robots.txt文件与页面中的meta robots标签所说的不匹配。
例如,robots.txt文件将页面从索引中隐藏了,但是Meta Robots标签里的说法却相反。
正确的做法应该是,如果你在robots.txt中对某个页面使用的Disallow,则在meta robots标签中就应该使用 noindex, nofollow。
根据我的经验,Google会优先考虑robots.txt文件中Disallow的内容。
但是,你可以通过明确告诉搜索引擎哪些页面应该索引,哪些不应该,来解决Meta Robots标签和robots.txt之间的说法不一致的问题。
写在最后
Robots.txt是一个简单、但是很强大的文件。明智地使用它,可以对SEO产生积极影响。随意使用它,可能会造成灾难性的后果。处理好Robots.txt和Meta Robots标签之间的配合使用问题,也能对SEO产品积极的影响。
希望这篇文章让你真正了解了如何使用robots.txt和Meta Robots标签。





